คืองี้ครับ ในวิชา Data Mining หรือ Machine Learning มันจะมีอยู่ปัญหานึงที่มักถูกหยิบยกขึ้นมานำเสนออยู่เสมอ นั่นคือ ปัญหาการจำแนกผลลัพธ์โดยการพิจารณาจากคุณสมบัติของข้อมูลที่ฝึกฝน เช่น ใช้ส่วนสูง หรือ น้ำหนัก ประกอบกัน เพื่อจะจำแนกว่าบุคคลคนนั้น เป็นนักบาสเก็ตบอลหรือนักซูโม่หรือนักมวย
ซึ่งถ้าในทางทฤษฎีเราสามารถจำแนกว่า นักบาสเก็ตบอลคือ Class ที่หนึ่งส่วนนักซูโม่ก็เป็น Class ที่สอง และนักมวยก็เป็น Class ที่สาม ดังนั้น ถ้าข้อมูลที่มีมันจำแนกได้มากกว่าสอง Class เราก็จะเรียกข้อมูลชุดดังกล่าวว่าเป็นข้อมูลที่ถูกจำแนกผลลัพธ์ได้เป็น Multi-Class ตัวอย่างข้อมูลก็เป็นดังรูปข้างล่าง
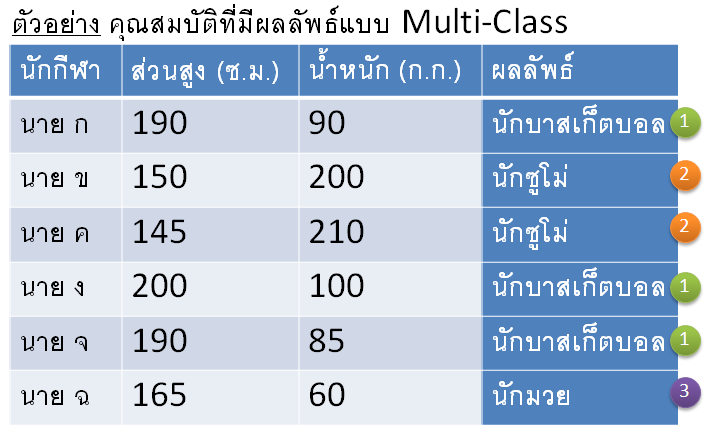
แต่ถ้าข้อมูลที่ต้องการจำแนก มันมีข้อมูลบางชุดที่มีคุณสมบัติเหมือนกันเป๊ะ ๆ แต่สามารถจำแนกเป็นผลลัพธ์ได้มากกว่าหนึ่ง Class เราจะเรียกข้อมูุลชุดดังกล่าวว่ามีลักษณะของ Multi-Label ดังรูป
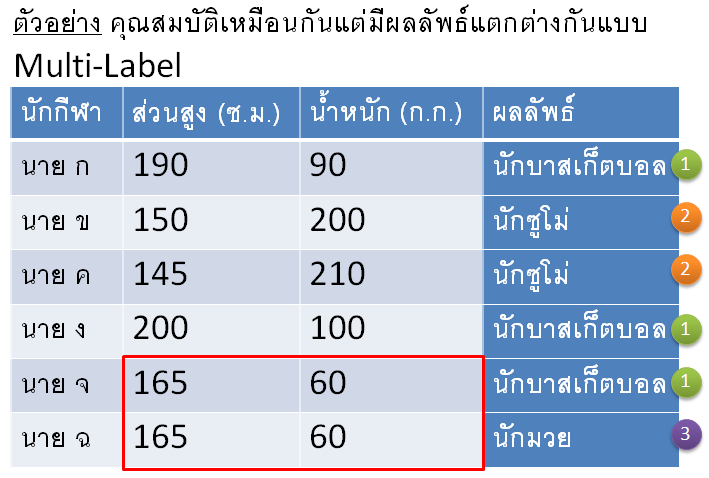
จากรูปจะเห็นว่า นาย จ กับ นาย ฉ มีส่วนสูงกับน้ำหนักเท่ากันเป๊ะเลย แต่กลับกลายเป็นว่า ด้วยส่วนสูงและน้ำหนักที่เท่ากันเป๊ะดังกล่าว กลับให้ผลลัพธ์ที่แตกต่างกัน
สำหรับคอมพิวเตอร์แล้ว การเรียนรู้เพื่อจำแนกผลลัพธ์ซึ่งมีมากกว่าสอง Class (Multi-Class) เป็นเรื่องที่ไม่ได้ยากอะไร แต่ถ้าหากว่าเป็นการจำแนกผลลัพธ์ที่แตกต่างกันมากกว่าหนึ่ง Class โดยเกิดจากคุณสมบัติที่เหมือนกัน (Multi-Label) เป็นเรื่องที่ไม่ง่าย ซึ่งวิธีแก้ความไม่ง่ายก็คือ
- การให้มันเรียนรู้จากคุณสมบัติของข้อมูลชุดที่เหลือเพื่อให้มันชั่งน้ำหนักในการจำแนกผลลัพธ์แทน หรือ
- การเพิ่มคุณสมบัติให้กับข้อมูล เช่น ถ้าส่วนสูงกับน้ำหนักมันทำให้จำแนกยาก งั้นก็เพิ่มความดันเลือดกับระดับน้ำตาลในเลือดเข้าไป เผื่อมันจะช่วยให้เห็นความแตกต่าง และทำให้การจำแนกเป็นไปได้ง่ายขึ้น เป็นต้น
ถึงตอนนี้ก็คงพอจะแยกออกแล้วนะครับว่า Multi-Class กับ Multi-Label มันแตกต่างกันยังไง

