ผมเห็นเดี๋ยวนี้ใคร ๆ ก็สร้างบล็อกส่วนตัวกัน แล้วก็หวังว่าจะมีคนเข้าไปอ่านกันมาก ๆ แต่เอาเข้าจริงแล้วพอมาตรวจสถิติก็กลับพบว่า ผู้ที่เข้ามาเยี่ยมเยียนบล็อกส่วนใหญ่นั้น มันดันเป็น web crawler ซะนี่!!!
ตั้งแต่ผมติดตั้งปลั๊กอิน Feed ก็เลยทำให้ผมได้รู้ว่าคนที่เข้ามาที่บล็อกแห่งนี้นั้น สนใจเรื่อง web crawler เป็นอันมาก นอกจากจะอ่านจากที่ผมเขียนแล้ว ก็ยังติดต่อผ่าน “ห้องติดต่อ” เพื่อมาถามไถ่ผมเกี่ยวกับเรื่อง web crawler อย่างไม่ขาดสาย
จริง ๆ แล้วกุญแจหลักของ web crawler มันไม่ได้อยู่ที่การแบ่งภาคเพื่อไต่ไปตามเว็บไซต์ต่าง ๆ หรอก อันนั้นจะเขียนให้โปรแกรมเป็นแบบ multithread หรือ multitasking ยังไงก็ได้
แต่ประเด็นหลักมันน่าจะอยู่ที่เมื่อเราได้ข้อมูลมาแล้ว เราจะตัดแบ่งยังไงให้มันได้อย่างที่เราต้องการมากกว่า เรียกว่าเอาแต่เนื้อ ๆ นั่นเอง ส่วนน้ำนี่เททิ้งให้หมดเลยไม่เอา
ซึ่งคำตอบสำหรับประเด็นนี้ก็คือการที่เราต้องเข้าอกเข้าใจ regular expression ให้มาก ๆ เพราะมันเป็นเครื่องมือที่ทุ่นแรงในการตัดแบ่งข้อความ มันเหมาะมากสำหรับใช้ในการประมวลผลคำ มันช่วยให้เราเขียนคำสั่งแค่บรรทัดเดียว แต่ทำงานเหมือนกับชุดคำสั่งหลายร้อยคำสั่งเลย!!!
แต่น่าเสียดายที่ regular expression นั้นเข้าใจยาก ถึงแม้จะมีหนังสือ Mastering Regular Expression พิมพ์ออกมาให้เราอ่าน (หนา 500+ หน้าแน่ะ หนาโคตร) หรือมีคนพยายามย่นย่อ regular expression ให้เป็นฉบับย่อเพื่อให้เราทำความเข้าใจอย่างรวดเร็วแล้วก็ตาม
สาเหตุที่มันเข้าใจยากก็คงเป็นเพราะ มันเป็นไวยากรณ์ที่ถูกออกแบบมาเพื่อการเขียน ไม่ใช่ไวยากรณ์ที่ถูกออกแบบมาเพื่อการอ่าน ดังนั้นเราจะพบว่าหากเราอ่านมันเข้าใจ นั่นย่อมแสดงว่าในสมองของเราได้บรรจุกลไกถอดรหัส regular expression เอาไว้เรียบร้อยแล้ว จึงไม่น่าแปลกใจที่จะมีหลาย ๆ คนอ่านมันแล้วไม่เข้าใจ!!!
ทีนี้พอเห็นว่ามันยาก แทนที่จะแก้ไขที่ต้นเหตุ เขาก็ไปแก้ปัญหาที่ปลายเหตุ โดยการสร้างเครื่องมือขึ้นมาเพื่อช่วยในการสร้างและทดสอบ regular expression อย่างเช่น RegexBuddy เป็นต้น ซึ่งแบบนี้มันก็ดีเหมือนกัน เพราะ regular expression มัน debug ลำบาก (debug ได้ด้วยเหรอ ไม่เคยรู้?) ยิ่งเขียนให้ซับซ้อนเท่าไหร่ ก็ยิ่ง debug ยากเข้าไปเท่านั้น ดังนั้นมีเครื่องมือมาช่วยก็ดี แต่แหม ดันต้องจ่ายเงินซื้อซะนี่!!!
ทุกคนก็ยอมรับในชะตากรรมกันไป ยอมรับกันว่ามันอ่านเข้าใจยาก แต่ถ้าเขียนออกมาแล้วมันกระทัดรัด มันทำงานได้อย่างมีประสิทธิภาพสูง ก็เลยทน ๆ ใช้กันไป ไม่คิดจะแก้ไขมัน
แต่มีนักพัฒนาซอฟต์แวร์บางคนเขาก็ไม่ยอมนะ ฝรั่งเองเขาก็รู้สึกว่าทำไมต้องมาเขียนอะไรที่อ่านยาก ๆ แบบนี้ มันต้องเปลี่ยนแปลงสิ ทำให้ regular expression มันเขียนออกมาแล้วอ่านเข้าใจง่าย แล้วก็ทำให้เป็น Framework ด้วย เพื่อแก้ปัญหาพื้นฐานที่ regular expression มีให้หมดเลย น่าจะดีกว่า
Let’s take the code out of source code
คำขวัญโดย Joshua Flanagan (Microsoft Certified Application Developer)
ยกตัวอย่างเช่น… ถ้าเราจะแกะข้อความใด ๆ ออกมาจาก tag ลิงก์ (ในที่นี้จะแกะคำว่า Apple ออกมา) …

เราก็ต้องเขียนไวยากรณ์ regular expression ประมาณนี้ … (เพื่อให้ได้คำว่า Apple ออกมา)
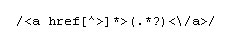
โหยยากอ่ะ งั้นขอเปลี่ยนเป็นงี้ได้ป่ะ?
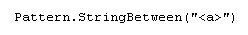
แบบนี้จะง่ายกว่าเยอะเน้อะ เป็น regular expression แบบอ่านได้ด้วย แถมเป็นแบบ OOP อีกต่างหาก จ๊าบไปเลย
ผมก็หวังว่าจะมีคนสร้าง regular expression framework ออกมาไว ๆ นะ เพราะผมขี้เกียจเรียน regular expression ชั้นสูงอ่ะ มันยาก T-T
[tags]regular,expression,framework,การสร้างซอฟต์แวร์,ซอฟต์แวร์,คอมพิวเตอร์[/tags]

เจ๋งไปเลยแฮะ คิดได้งัยเนี่ย เปลี่ยนไวยากรณ์ให้กลายเป็นแบบ OOP ที่คนที่ไม่ค่อยเก่งซักเท่าไหร่ อย่างเราๆ น่าจะสามารถใช้งาน Regular Expression ได้อย่างง่ายๆ พี่ไท้คิดได้งัยเนี่ย…
ที่ยังไม่มีออกเป็น framework หรือ library ให้เราเรียกใช้ได้ง่ายๆ ก็คงเพราะคนที่ใช้ regular จริงๆ จังๆ ส่วนใหญ่เก่ง และใช้ในเรื่องที่มันเฉพาะ ไม่ได้เป็นกรณีทั่วๆ ไป
แต่อย่างที่พี่ไท้ยกตัวอย่างการ extract คำจาก html tag a ผมก็เห็นว่ามีประโยชน์นะครับ ถ้ามีพวก html extractor ออกมาก็น่าจะดี เพราะน่าจะเป็นกรณีการใช้ regular expression ที่มีคนใช้มากสุด
อ้อ…ผมก็เคยไปหา download library ในการ extract แต่ละชิ้นจาก html tag a นะครับ เป็นภาษา php ซึ่งก็ง่ายดี อย่าง PEAR ของ php นี่ผมว่าน่าจะมีคนทำ package Regx (Regular Expression) บ้างนะครับ แต่ละคนที่ใช้แต่ละเรื่องจะได้เอามารวบรวมไว้ที่นี่เป็นศูนย์กลาง (ตรงตาม cencept ของ PEAR เด๊ะ)
Hpricot – http://code.whytheluckystiff.net/hpricot/
ตัวอย่างด้วยภาษา Ruby
require ‘hpricot’
doc = Hpricot.parse(“apple“)
puts (doc/”a”).innerHTML #=> “apple”
หรือจะส่งเป็น url ไปเลยก็ได้ครับ มันจะ parse ออกมาแล้วใช้ selection อย่าง
“img#logo” #
“img.thumb” #
ถ้ามีหลายๆ ก้อน มันจะส่งกลับมาเป็น array ครับ
อาจจะไม่ตรงกับ regexp framework แต่ดูจากลักษณะการทำงานแล้วใกล้เคียงกับที่พี่ไท้ต้องการครับ
แก้ไข code ข้างบนครับ มันดัน render เป็น html code จริงๆ
require 'hpricot'
doc = Hpricot.parse "<a>apple</a>")
puts (doc/"a").innerHTML #=> "apple"
"img#logo" #<img src="image.jpg" id="logo" />
"img.thumb" #<img src="image.jpg" class="thumb" />
ช่่วยได้เยอะนะผมว่า RegEx ไรเนี่ย เคยคิดจะเอามาใช้จริงจัง แต่เห็นไวยากรณ์แล้วสะดุ้ง – -“
ถ้ามองในมุม crawler ผมว่าใช้ DOM ไปเลย แจ่มกว่าครับ
ส่วนเรื่อง regex framework คงจะสร้างมาเพื่อแทน raw regex ไม่ได้น่ะครับ น่าจะออกมาเป็นในรูปแบบของ helper มากกว่า (อาจจะใช้พวก method chaining เข้ามาช่วยเพิ่มความหะรูหะราได้ แถมอ่านง่ายขึ้นด้วย)
$regex->StringBetween(““, ““)->AnyPosition()->OnlyFirstMatch();
$regex->StringBetween(““, ““)->AtLineStart()->MatchAllLine();
ผมไม่ได้เป็นคนคิดครับคุณโอ๋ มีคนคิดก่อนไปแล้ว ผมแค่ขยายความให้ทราบเฉย ๆ จ้า
ก็อย่างที่คุณ rux ว่านั่นแหล่ะครับ อะไรที่มันใช้บ่อย ๆ ก็น่าจะเอามาทำเป็น framework เน้อะ
โอ้ เป็นไวยากรณ์ที่ผมไม่เคยเห็นมาก่อนเลยครับคุณ punneng
ผมเห็นครั้งแรกสะดุ้งโคตรครับคุณ penguin เห็นสมัยตอนภาษา pearl โน่นแน่ะ น๊านนานมาแล้ว
ผมเห็นนักพัฒนาที่ microsoft เขาก็พยายามจะทำเป็นแบบที่คุณ AMp ว่า แล้วยัดเอาไว้ใน .NET Framework นะั แต่ไม่รู้ว่าตอนนี้ไปถึงไหนแล้ว
Hpricot นี่ออกแนว css selector แฮะ
ถ้ามีจริงๆ ก็คงดีครับ ผมก็ใช้ Regular Expression บ่อยอยู่เหมือนกันแต่ทว่าก็ยังอยากได้ Framework อยู่ดี ~o~
ส่วนใหญ่ถ้าไม่ใช้ Regular Expression ผมก็ใช้ jQuery ท่อง DOM เนี้ยและสะดวกสุดๆ
AMp: แม่นแล้ว
ดูแล้วปวดหัวจริงๆ ด้วย